Author: Hadar Averbuch-Elor
Home < Hadar Averbuch-Elor
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Who’s Waldo? Linking People Across Text and Images
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
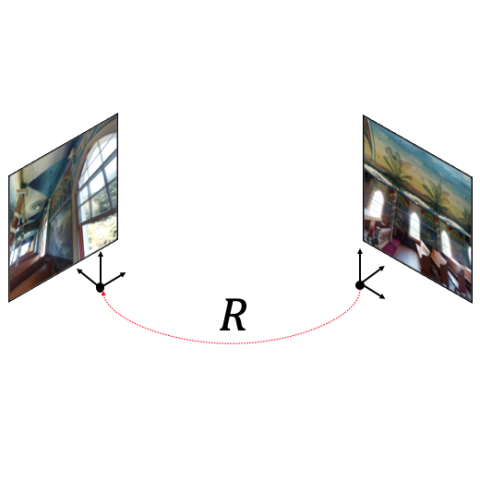
Extreme Rotation Estimation using Dense Correlation Volumes
Learning Gradient Fields for Shape Generation
DualSDF: Semantic Shape Manipulation using a Two-Level Representation